Ubuntu本地部署DeepSeek-R1模型+chatbox构建私人专属AI助手
在当今数字化时代,拥有一个专属的AI助手无疑会大大提高我们的工作效率和生活质量。本文将详细介绍如何在Ubuntu系统上本地部署DeepSeek-R1模型,并通过将其集成到应用中,从而构建一个私人专属的AI助手。
前置准备
在开始部署之前,确保你的系统和硬件满足以下要求:
- 系统:Ubuntu 20.04 或更高版本
- 硬件:Intel Core I9-13900K 、Nvidia A6000(48G显存)
- 软件:Conda、cuda、Pytorch
部署流程
1. 安装 Ollama
在 Ubuntu 中,可以通过以下命令直接安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh |
由于国内网络原因,安装可能会比较慢,如果降速可以先Ctrl c 终端再续上。
安装完成后,你将看到类似以下的信息。运行 ollama -v 命令,可以输出 Ollama 的版本号。安装脚本会将 Ollama 设置为开机自动启动的服务,并通过 systemd 服务管理工具确保其在系统启动时运行,以及在异常退出时自动重启。
2. 部署 DeepSeek 推理模型
根据你的实际环境配置,选择合适的 DeepSeek 模型进行部署。如果你是初次安装,或者显卡资源有限,建议先安装 1.5B 或 7B 尺寸的模型。
运行以下命令安装 DeepSeek R1 模型:
ollama run deepseek-r1:32b |
这里我选择的是 32b 模型,即 DeepSeek-R1-Distill-Qwen-32B。这是基于 DeepSeek-R1 和 Qwen 蒸馏后的模型,其性能在官网上有如下描述:DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中优于 OpenAI-o1-mini,为密集模型实现了新的最佳性能。
在命令行中使用模型体验较差,接下来我们 将 DeepSeek 模型集成到 chatbox 应用中。
3. 下载chatbox
4. 将 DeepSeek 模型接入 chatbox
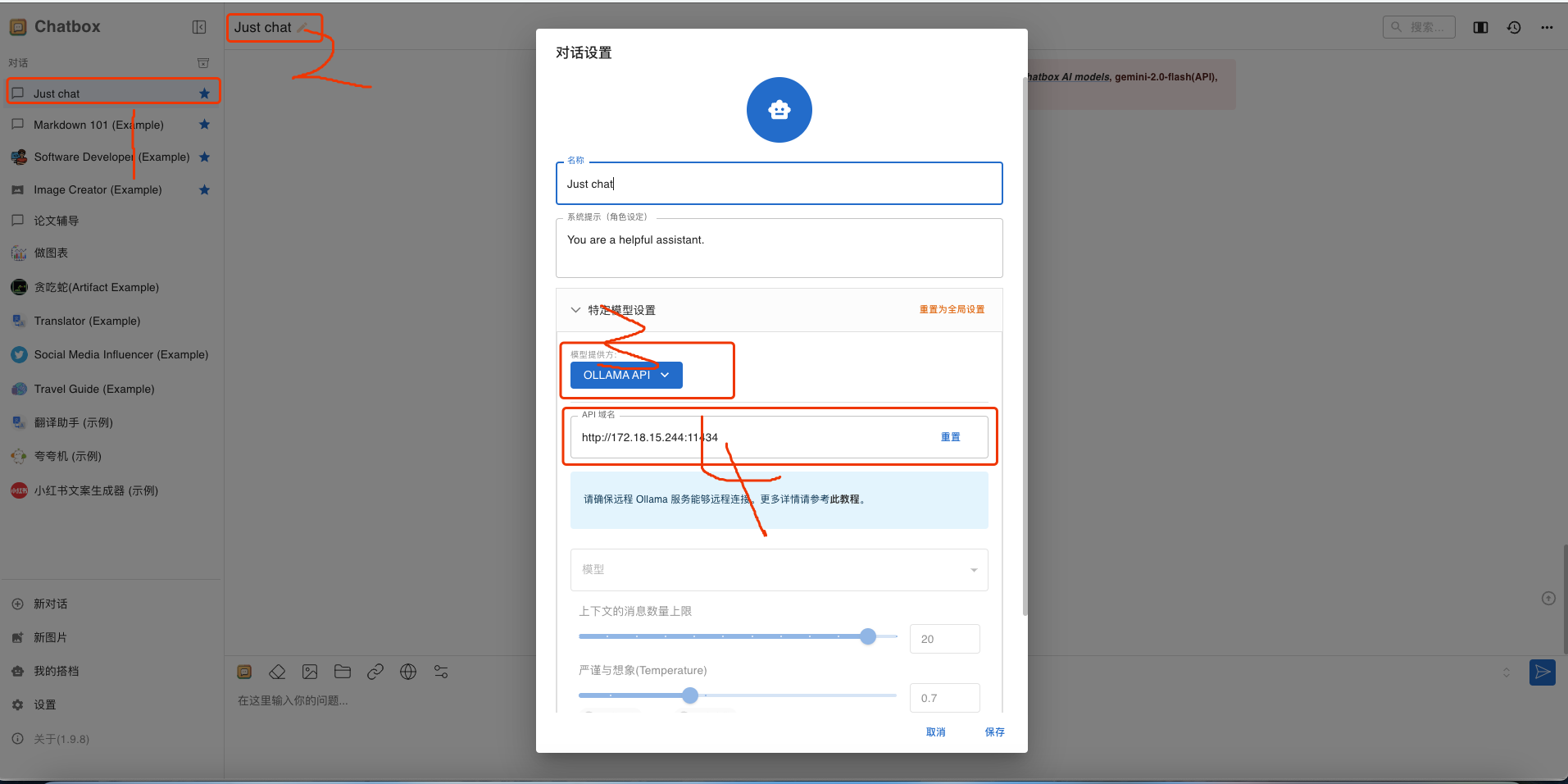
在 chatbox 平台右上角点击just chat → 设置 → 模型供应商,选择 Ollama,并点击“添加模型”。
添加配置信息如下:
- Model Name:填写具体部署的模型型号。例如,上文部署的模型型号为
deepseek-r1:32b。 - Base URL:填写 Ollama 客户端的运行地址,通常为
http://your_ollama_server_ip:11434。 - 其他选项可以保持默认值或根据实际需要填写。
5.本地与ollama的远程服务进行对接。
在 MacOS 上配置
打开命令行终端,输入以下命令:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"重启 Ollama 应用,使配置生效。
在 Windows 上配置
在 Windows 上,Ollama 会继承你的用户和系统环境变量。
通过任务栏退出 Ollama。
打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。
点击编辑你账户的环境变量。
为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *****。
点击确定/应用以保存设置。
从 Windows 开始菜单启动 Ollama 应用程序。
在 Linux 上配置
如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量:
调用
systemctl edit ollama.service编辑 systemd 服务配置。这将打开一个编辑器。在 [Service] 部分下为每个环境变量添加一行 Environment:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"保存并退出。
重新加载 systemd 并重启 Ollama:
systemctl daemon-reload
systemctl restart ollama
启动:ollama run deepseek-r1:32b
参考链接
 wechat
wechat alipay
alipay